|
Title: REMS
Authors: Clare Tagg (Tagg Oram Partnership,
www.taggoram.co.uk), Somia Nasim and Peter Goff (The Qualifications & Curriculum Development Agency, www.qcda.org.uk)
Working with data
In the first six months of REMS most of the work on the NVivo project involved collecting, importing and coding the data. During this period a naming convention was designed for source documents, a classification system was developed using attributes and a coding framework was developed and refined. During this pilot phase the protocols for merging the project were developed; these were necessary because NVivo only allows one simultaneous user and it was clear from the outset that several people would need to work on coding at once.
Data sorting
The source naming convention in NVivo is extremely important as it determines how the software organises the evidence. The team knew that this was going to be important and spent some time designing the naming convention. Both the date of the source and the reform strand it relates to were important. Storing sources by strand was considered with a sub-folder for each strand. However as sources were applicable to multiple strands and chronological ordering of evidence was vital, after a detailed discussion it was decided that date was key as this would allow us to build up the story over time.
The strand element was not lost as acronyms for the strands were added into the naming convention. The naming convention employed in REMS is - Year-month-strand-author-title-plus rating. This allows the team to search for sources by strand or author but evidence is always displayed chronologically (for more information go to www.taggoram.co.uk/research/NVivotips).
Classification
The naming convention is one way to sort the evidence reports, but in order for the database to function in a more sophisticated manner, further information about each source was required. In NVivo this is achieved by designing attributes and applying attribute values to each source case (more information is at www.taggoram.co.uk/research/NVivotips). This was probably one of the easiest areas to develop.
Each attribute was designed to be simple and easy to apply but with analysis in mind (eg to allow sources published in 2009 about implementation issues to be selected). The main problem we encountered was that, for each attribute you are only able to select one value. For example, we needed to know which reform strand each source relates to, and we knew that sometimes a source may relate to more than one strand. So a separate attribute was added for each of the strands with yes/no values. Eighteen months into the project, each document is classified according to 35 attributes .
Coding
All databases apply tags or classifications, but the REMS system uses qualitative research techniques to apply coding to the content of each evidence source. Before we were able to do this we needed to develop a coding framework. This aspect of the system was probably the most difficult to design as the normal research approaches were inapplicable. REMS does not have research objectives so it was not possible to use these as a starting point. It was also not possible to use a grounded approach as the sources were very varied and contained much that was interesting but not particularly relevant. Instead we used the 14-19 Reform policy objectives as a guide, together with QCDA's objectives and remit in relation to these. We knew the coding framework needed to be flexible enough to deal with short, medium and longer-term issues, comprehensive enough to deal with a range of queries and interrogation, and simple enough to make coding easy for multiple coders.
As you can imagine it took several iterations before we finalised the framework. The framework consists of two levels of themes (or nodes as they are known in NVivo) and each theme is fairly high level (for more details on developing a node tree in NVivo see www.taggoram.co.uk/research/NVivotips). For each theme a title and definition was created in NVivo, so we all knew what should be coded to each theme and to maintain consistency in the coding. Once a draft coding framework was formulated, tests were conducted to clarify how the coding would work. When we felt that the framework was ready, we piloted it using a range of different types and sizes of source. Although, the framework is not static and we can add and remove nodes, as a team we decided for consistency this would only be done on a quarterly basis.
Coding policy
The diagram below illustrates the coding policy and framework (See www.taggoram.co.uk/research/cases/REMS.
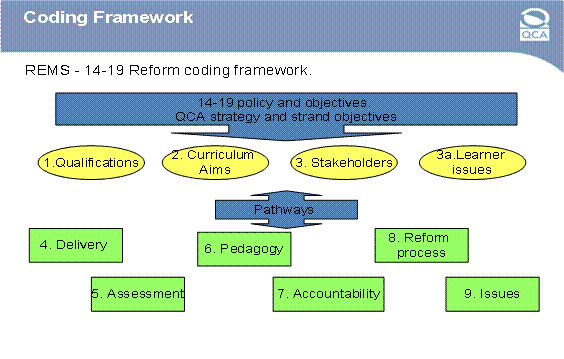
The strategy adopted was to multi-code each piece of evidence to between 4-6 nodes designed as follows:
- A set of nodes was developed as an initial portal based on 'qualifications'.
- A similar set of nodes was developed for each 'Curriculum Aim' and 'Stakeholder'.
- A strategy was adopted of coding all evidence initially to these top 3 areas.
- A series of nodes covered Delivery, Assessment, Pedagogy, Accountability and Reform process; at least one must be selected to code the extract.
- A set of nodes identified important cross-cutting issues arising during the reform (eg Academic vocational divide).
When coding, careful consideration was given to the selection of a passage of a source to code:
- It needed to be useful as evidence and as such worth coding to the nodes representing Delivery, Assessment, Pedagogy, Accountability and Reform process.
- It should not duplicate evidence coded in the same source; for this reason we decided that in general executive summaries, introductions and conclusion would not normally be coded.
- We would not code research method so generally sections on methodology and appendices were not coded.
- The text selected for coding would be sufficient to convey meaning but as far as possible would be short enough to only refer to one idea; NVivo annotations were used to add context when this might not be obvious from the selection of a small item of evidence (such as a bullet point).
Detailed training of the coders has been conducted to cover both NVivo and the coding conventions of REMS. In addition, Peter Goff, has taken on a role of guardian or chief examiner of the coding framework and has regularly reviewed the coding. We experimented with NVivo's automatic tools for intercoder reliability but found that these provided too much detail to be usable. Peter relies on reading the source and using NVivo's density bar to check which extracts have been coded and the relevance of that coding. A coding policy and training manual was devised to further maintain coherence and understanding between different coders (See www.taggoram.co.uk/research/cases/REMS.)
For the team the coding is the crucial backbone of the system and if this is not controlled and reviewed, it could jeopardise the system's reliability. Therefore, the team devised strict quality control measures, managed by Somia, for the coding as well as checks on all the systems features e.g. classifications and set development. Some of these were manual checks conducted by the team and others were query checks developed in NVivo. These checks of the coding and whole system are conducted on a quarterly basis.
Difficulties in Coding
The intense training provided to coders, as well the quality control procedure utilised, has helped to make the coding successful. However, the team encountered some difficulties with the coding.
- As we were incorporating a range of different sources, authored and written in various styles this sometimes made the coding slightly problematic.
- Both the size of the passage and the coder's desire to record all aspects reflected in the extract, sometimes lead to over coding.
- As we coded, some of the nodes definitions needed revising.
- The coders' knowledge and expertise of the education and skills sector affected the coding.
Qualitative coding is not an exact science and is open to interpretation, but we feel that the node definitions, the structure of the nodes, the training and quality control by the team, have resulted in an adequately good consistency.
Merging the Project
NVivo is a single-user system so to have multiple coders working on the project it was necessary for each coder to have their own project database and periodically to merge these into a single master project. This process was managed by Somia, who created batch projects for the coders containing only the coding framework and the sources for them to code. Each coder used the standard coding framework, coding to 'Other' nodes where necessary. Once the coding had been completed, the batches were merged into the master REMS project (for more information on merging in NVivo go to www.taggoram.co.uk/research/NVIvoTips.)
This merge process worked well for the batches. When some recoding was done on the master project as part of one of the quarterly reviews, it was difficult to merge the master projects because:
- it was difficult to isolate the different parts of each master project that needed to be included
- the size of the master projects made merging very slow.
As a consequence, subsequent recoding will take account of the merge issues. Back to Project Home Page
|







